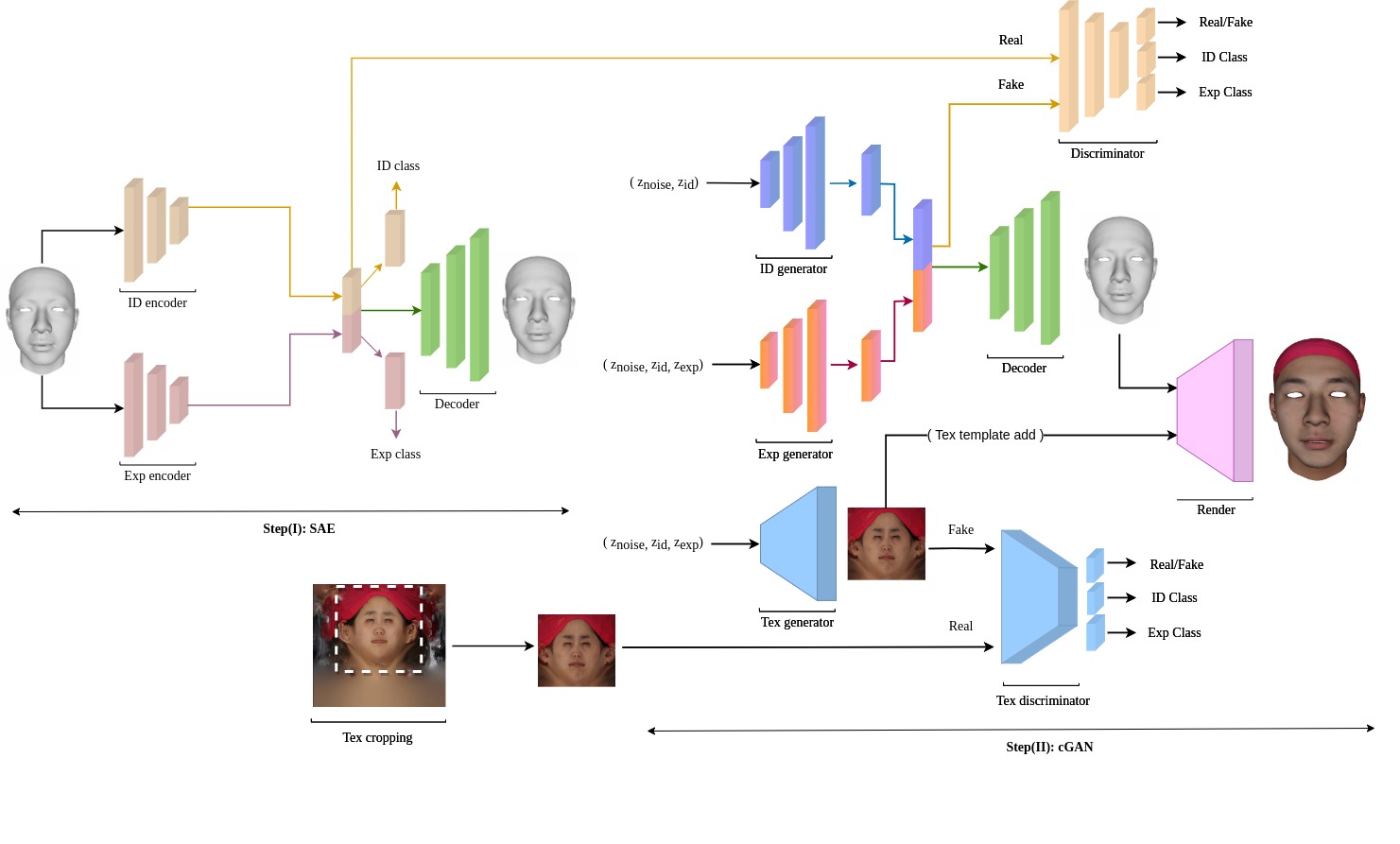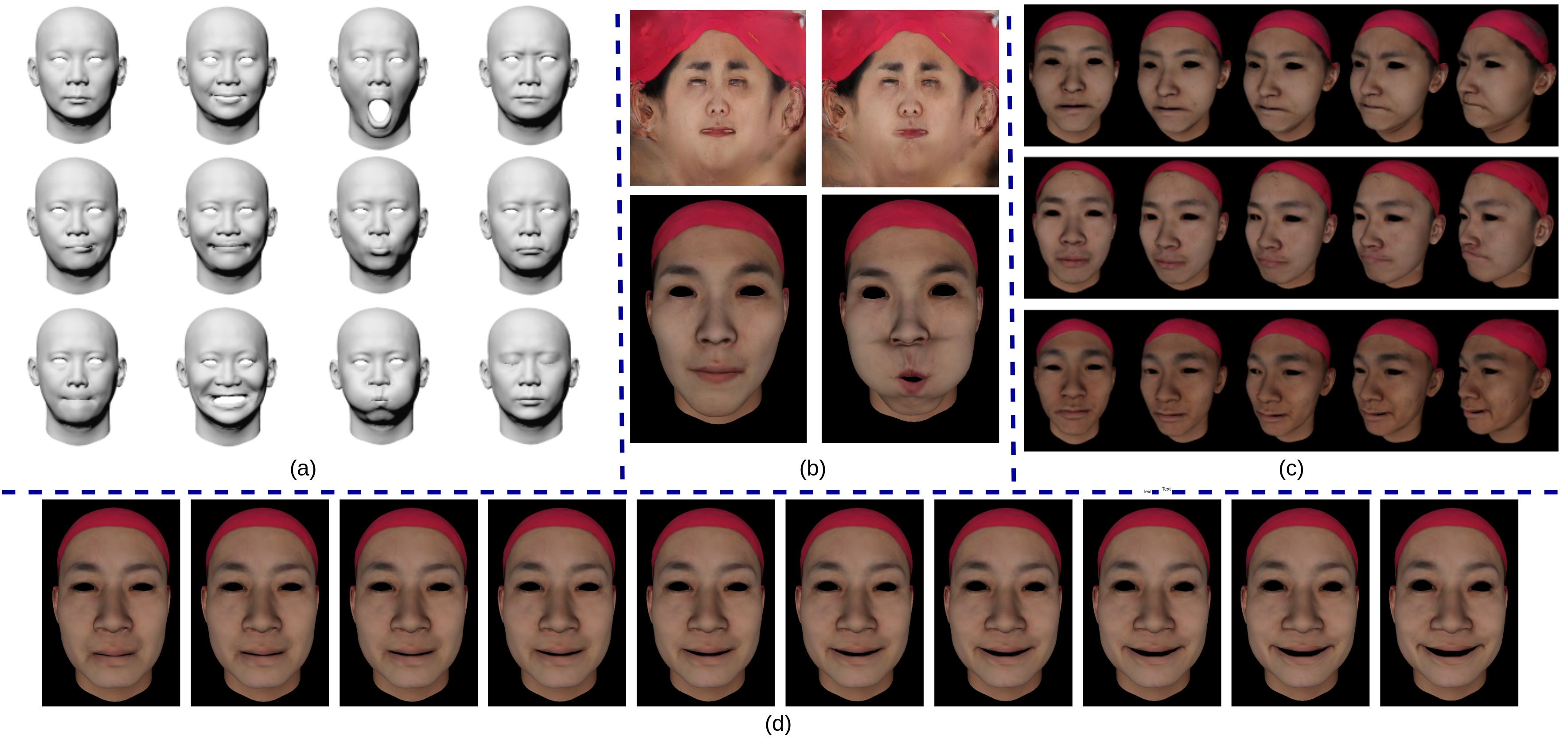
Our generator’s uncurated set of shapes, textures and rendered faces with the FaceScape dataset. (a) Shapes of different expressions belonging to the same identity. (b) Expression-specific generated textures and corresponding rendered faces. (c) Each row shows multi-view extrapolation of the expression intensity while preserving the identity. (d) Facial expression (Smile) synthesis with different monotonic intensity.